这是最常见的问题之一。你可以通过互联网寻找这个问题的答案。不过,我不确认我的设计是否 100% 正确,但希望给你一些参考。
前段时间,我有幸见到了 Robert Griesemer[1](Go 的作者之一)。我们问了他这个问题:“如何组织 Go 代码?”。他说:“我不知道。” - 这很显然并不令人满意,我知道。当我们问他如何设计他的代码时,Robert 说他总是从扁平结构开始,并在必要时创建包。
我花了很多时间在生产应用程序的两个宠物项目中尝试不同的方法。在本文中,我将向你展示所有选择并告诉你它们的优缺点。阅读完这篇博文后,你将不会有一种“统治所有模式的模式”。
01 在我们开始之前
无论你如何组织代码,你都必须考虑阅读它的人。最重要的是你不应该让你的贡献者或同事思考。把所有东西都放在明显的地方。不要重新发明轮子。你还记得 Rob Pike[2] 说过的关于 go fmt 的话吗?
Gofmt 的风格没有人喜欢,但 gofmt 是每个人的最爱。
你可能不喜欢众所周知的模式。坚持下去对我们和整个社区都更好。但是,如果你有充分的理由做出不同的决定,那也没关系。如果你的包设计良好,源代码树会很好地反应出来。
让我们从文档开始。每个开源 Go 项目在 pkg.go.dev[3] 上都有它的文档。对于每个包,你首先看到的是包的概述。以net/http包为例,在描述每个公共函数、常量或类型之前,你需要对包提供的内容进行描述。你可以从中学习如何使用 API 和更深入的细节。从哪个来源生成概览?该net/http包有一个 doc.go[4] 文件,作者在其中放置了该包的一般描述。你可以将此概述放在文件夹中的任何其他文件中,但 doc.go 大家公认的标准。
那么Readme文件中应该有什么?首先,对这个项目的总体概述——它的目标。然后,你应该有一个快速入门部分,你可以在其中描述开始处理项目时应该做的事情,包括任何依赖项,如 Docker 或我们正在使用的任何其他工具。你可以在此处找到基本示例或指向更详细描述项目的外部网站的链接。你必须记住,此处应保留的内容取决于项目。你必须从读者的角度思考。什么信息对他们最重要?
当你有更多文档要提供时,将它们放入docs文件夹中。不要将它们隐藏在像/common/docs 中。这种方法有好处:很容易找到,并且在一个拉取请求中,你可以更改公共 API 及其文档。你不必克隆另一个存储库并在它们之间同步更改。
我的下一个建议可能让你吃惊。我建议使用众所周知的工具,例如make,我知道有一些替代品,例如 sake[5], mage[6]、zim[7]或 opctl[8]。问题是要开始使用它们,你必须学习它们。如果任何项目都使用不同的自动化工具,新维护人员将更难开始。我的观点是你应该明智地选择你的工具。你使用的工具越多,项目启动工作就越困难,特别有新人加入。
我一直在从事一个项目,我必须在本地运行 2 个不同的依赖项,在 CLI 中登录到 AWS 帐户,并连接到 虚拟网络才能在我的 PC 上运行测试。基本设置需要一两天才能完成,我想我不必告诉你这些测试有多么不稳定[9]。
关于 linting 建议使用 golangci-lint[10]。启用对你的项目来说似乎合理的所有 linter。通常使用默认启用的 linter 规则可能是一个好的开始。
02 扁平结构(单包)
让我们从最推荐的方法开始:只要你不被迫添加新包,就将整个代码保存在根文件夹中。在项目开始时,这种方式真的挺好。当我开始使用它时,我发现它很有帮助,并且对它最终将如何工作有一个模糊的想法。
将所有内容放在一个地方有助于避免包之间的循环依赖。当你将某些内容放入单独的包时,你会发现需要根文件夹中的其他内容,你将被迫为此共享依赖项创建第三个包。随着项目的发展,情况变得更糟。你最终可能会拥有许多包,其中大多数包几乎都依赖于其他包。许多函数或类型必须是公开的。这种情况模糊了 API,使其更难阅读、理解和使用。
使用单个包,你不必在文件夹之间跳来跳去并思考架构,因为所有的内容都在一个地方。这并不意味着你必须将所有内容都保存在一个文件中,例如:
- courses/
- main.go
- server.go
- user_profile.go
- lesson.go
- course.go
在上面的例子中,每个逻辑部分都被组织成单独的文件。当你犯了错误并将结构放入错误的文件时,你所要做的就是将其剪切并粘贴到新位置。你可以这样考虑:单个文件代表应用程序的一个实体部分。你可以按代码(HTTP 处理程序、数据库存储库)或其提供的内容(管理用户的配置文件)对代码进行分组。当你需要某样东西时,你就会知道在哪里可以找到它。
什么时候创建一个新包?如果你有充分的理由这样做,比如:
1)当你有不止一种启动应用程序的方式时
假设你有一个项目,并且希望以两种模式运行它:CLI 命令和 Web API。在这种情况下,创建一个/cmd包并包含 cli和web子包是很常见的。
- courses/
- cmd/
- cli/
- main.go
- config.go
- web/
- main.go
- server.go
- config.go
- user_profile.go
- lesson.go
- course.go
你可以将多个main()函数放入单个文件夹中的单独文件中。要运行它们,你必须提供一个明确的文件列表来编译,而其中只有一个要 main()。这使应用程序的运行变得非常复杂。更简单的方式是直接输入 go run ./cmd/cli。
当你有一个子包时,./cmd/ 文件夹的使用可能听起来过于复杂。我发现它在需要添加时很有用,例如,使用来自消息代理的消息。此主题将在拆分依赖项的部分中更详细地介绍。
2)当你想提取更详细的实现时
标准库就是一个很好的例子。让我们看看 net/http/pprof[11] 包。该net包为网络 I/O 提供了一个可移植的接口,包括 TCP/IP、UDP、域名解析和 Unix 域套接字。你可以根据此包提供的内容构建你想要的任何协议。net/http 包使我们能够发送或接收 HTTP 请求。HTTP 协议使用 TCP/UDP,因此http包是 net 的子包是很自然的。net/http/pprof包中的所有类型和方法都可以返回 HTTP 协议,因此自然是一个 http 子包。
database/sql包也是如此。如果你有更多非关系数据库的实现,它们将放在database包下,和 sql包同级。
你看出来模式了吗?数据包(packet )在树中(tree)越深,传递的细节就越多。换句话说,每个子包都在父包上提供了更具体的实现。
3)当你开始为密切相关的事物添加公共前缀时
一段时间后,你可能会注意到,为了避免误解或命名冲突,你开始为函数或类型添加前缀或后缀。通过这样做,我们试图模拟项目中缺少包的情况可能是一个好兆头。很难说什么时候提取新的子包。每次当你看到它提高了 API 的可读性并使代码更清晰时请提取新的子包。
- r:=networkReader{}
- //
- r:=network.Reader{}
如你所见,扁平结构既简单又强大。在某些用例中,你可能会发现它很有用且很有帮助。这种组织代码的方式不仅仅适用于小型或新建项目。以下是遵循单包模式的库示例:
- https://github.com/go-yaml/yaml
- https://github.com/tidwall/gjson
值得记住的是,你不需要不惜一切代价坚持这种组织代码的方式。保持简单是有原因的,但添加更多包可能会使你的代码更好。不幸的是,没有银弹。你需要做的是尝试并询问你的同事或维护人员哪个选择对他们来说更具可读性。
03 模块化
之前描述的组织代码的方式在某些场景可能效率不高。我花了很多时间试图获得“正确的”项目结构。一段时间后,我注意到对于业务应用程序,我开始尝试另一种类似的方式组织代码。
当我们开发直接为客户提供客户端的应用程序时,扁平结构可能效率不高。你希望创建提供一组与控制器、基础设施或业务领域的一部分相关的功能的模块。让我们仔细看看两种最流行的方法,并谈谈它们的优缺点。
按种类(kind)组织
这个模型很受欢迎。我认识的人没有提倡使用这种策略来组织代码的,但我在新旧项目中都发现了它。按种类组织是一种策略,它试图通过将部分放入基于其结构的桶中,从而为过于复杂的代码单元带来秩序。将包称为repositories 或 model 是很常见的。这样做的结果是你会创建类似 utils 或者 helpers 的包,因为你觉得应该把一个函数或一个结构放在一个单独的地方,但没有找到任何合适的地方。
- .
- ├──handlers
- │├──course.go
- │├──lecture.go
- │├──profile.go
- │└──user.go
- ├──main.go
- ├──models
- │├──course.go
- │├──lecture.go
- │└──user.go
- ├──repositories
- │├──course.go
- │├──lecture.go
- │└──user.go
- ├──services
- │├──course.go
- │└──user.go
- └──utils
- └──stings.go
在上面的示例中,你可以看到项目是按类型组织的。你什么时候想添加新功能或修复与课程相关的错误,你会从哪里开始寻找?在一天结束时,你将开始从一个包跳到另一个包,希望能在那里找到有用的东西。

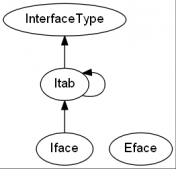
Graph that shows dependencies between packages
这种方法有其后果。每个类型、常量或函数都必须是公共的,才能在项目的另一部分中访问。你最终将大多数类型标记为公有。即使对于那些不应该公开的人。它混淆了应用程序的这一部分中的重要内容。其中许多是可能随时更改的细节。
另一方面,按种类组织对我们来说是很自然的。我们是在处理程序或数据库表的类别中思考的技术人员。这就是我们的成长方式,也是我们被教导的方式。如果你没有经验,这种方法可能更有益,因为它可以帮助你更快地开始。从长远来看,你可能会遇到不便,但这并不意味着你的项目会失败 — 恰恰相反,有很多成功的应用程序都是以这种方式设计的。
按组件组织
组件是应用程序的一部分,它提供独立的特性,很少或没有外部依赖。你可以将其视为插件,当你将其中之一移除时,整个应用程序仍然可以运行,但功能有限。它可能发生在运行数月或数年的生产应用程序中。
应用程序可能具有一个或多个提供业务价值的核心组件。在领域驱动设计术语中,组件是有界上下文。我们将在以后的文章中用 Go 的上下文来描述 DDD。
包的 API 应该描述包提供的内容而不是更多。它不应该暴露任何从消费者的角度来看不重要的低级细节。它应该尽可能简约。消费者可能是另一个包或另一个导入我们代码的开发人员。
该组件应包含提供业务价值所需的一切。这意味着,每个存储、HTTP 处理程序或业务模型都应该存储在文件夹中。
- .
- ├──course
- │├──httphandler.go
- │├──model.go
- │├──repository.go
- │└──service.go
- ├──main.go
- └──profile
- ├──httphandler.go
- ├──model.go
- ├──repository.go
- └──service.go
由于以这种方式组织代码,当你拥有与任务相关的课程时,你就知道从哪里开始寻找。它没有分布在整个应用程序中。然而,要实现良好的模块化并不容易。可能需要多次迭代才能实现一个好的封装 API。
还有一个挑战。如果这些包相互依赖怎么办?假设你想在用户的个人资料上显示最近的课程。它们应该共享相同的存储库或服务吗?
在这种特殊情况下,从个人信息(profile)文件的角度来看,课程是一种外部依赖。解决该问题的最佳方法是在 profile 必须需要的方法的包中创建一个接口。
- typeCoursesinterface{
- MostRecent(ctxcontext.Context,userIDstring,maxint)([]course.Model,error)
- }
在course包中,你公开了一个实现此接口的服务。
- typeCoursesstruct{
- //maybesomeunexportedfields
- }
- Func(cCourses)MostRecent(ctxcontext.Context,userIDstring,maxint)([]Model,error){
- //returnmostrecentcoursersforspecificuser
- }
在main.go中你从course包中创建Courses的结构实例并将其传递给profile包。在profile包中的测试中,你创建了一个 mock 实现。因此,你甚至可以在没有course实现包的情况下开发和测试 profile 功能。
如你所见,模块化使代码更具可维护性和可读性,但它需要你更加努力地思考你的决策和依赖关系。该逻辑可能看起来非常适合新包,但似乎太小了。另一方面,在处理项目期间,现有包的部分可能会开始增多,并在一段时间后提升为自主代码段。
当代码在包内部增多时,你可能会问自己:如何组织单个模块内部的代码?这是另一个难以回答的问题。在本节中,我展示了使用应用程序组件时的扁平结构。但是,有时这还不够……
04 简洁的架构
你可能听说过以下术语:Clean Architecture[12]、Onion Architecture 或类似术语。Uncle Bob 写了一本书[13],详细描述了每一层的含义以及应该或不应该包含的内容。这个想法很简单。你的应用程序或模块有 4 层(取决于你的代码库有多大):Domain、Application、Ports、Adapters。在某些来源中,名称可能不同。例如,作者没有使用 Ports 和 Adapters,而是使用 Inbound 和 Outbound。核心思想类似。让我们用例子来描述每一层。
Domain
这是我们应用程序的核心。每个业务逻辑都应该在这里。这意味着如果更改或添加任何业务需求,你必须更新我们的域部分。这个包应该没有任何外部依赖。它不应该知道这段代码是在哪个上下文中执行的。这意味着,它不应该依赖任何基础设施部分或知道任何 UI 细节。
- course:=NewCourse("HowtouseGowithsmartdevices?")
- s:=course.AddSection("Gettingstarted")
- l:=s.AddLecture("InstallingGo")
- l.AddAttachement("https://attachement.com/download")
- //etc
请注意,此时你并不关心课程的存储位置或如何添加新课程(使用 HTTP 请求或使用 CLI)。在domain包中,你描述了课程可能包含的内容以及你可以对其进行的操作。就这些!
Application
该层包含应用程序的每个用例。它是基础设施和 Domain 之间的粘合点。在这个地方,你获得输入(从它来自的任何地方),将其应用于域对象,然后将其保存或发送到其他地方。
- func(cCourse)Enroll(ctxcontext.Context,courseID,userIDstring)error{
- course,err:=c.courseStorage.FindCourse(ctx,courseID)
- iferr!=nil{
- returnfmt.Errorf("cannotfindthecourse:%w")
- }
- user,err:=c.userStorage.Find(ctx,userID)
- iferr!=nil{
- returnfmt.Errorf("cannotfindtheuser:%w")
- }
- iferr=user.EnrollCourse(course);err!=nil{
- returnfmt.Errorf("cannotenrollthecourse:%w")
- }
- iferr=c.userStorage(ctx,user);err!=nil{
- returnfmt.Errorf("cannotsavetheuser:%w")
- }
- returnnil
- }
在上面的代码中,你可以找到用户注册课程的用例。它是两部分的组合:与域对象(User,Course)和基础设施(存储和获取数据)交互。
Adapters
适配器也称为 Outbound 或基础设施(Infrastructure)。该层负责与外界存储和获取数据。它可以是数据库、blob 存储、文件系统或其他(微)服务。通常,该层在应用程序层的接口中具有其表示形式。它有助于在不运行数据库或将文件写入文件系统的情况下测试应用程序层。
适配器是对低级细节的抽象,因此你软件的其他部分不必“知道”你使用的是哪个数据库版本、SQL 查询长什么样或你存储文件的位置。
Ports
Ports(称为 Inbound)是应用程序的这一部分,负责从用户那里获取数据。它可以是 HTTP 处理程序、事件处理程序或 CLI 命令。它获取用户的输入并将其传递给 Application 层。此操作的结果返回到 Port。
- funcenrollCourse(whttp.ResponseWriter,r*http.Request){
- body,err:=io.ReadAll(r.Body)
- iferr!=nil{
- w.WriteHeader(http.StatusBadRequest)
- logger.Errorf("cannotreadthebody:%s",err)
- return
- }
- req:=enrollCourseRequest{}
- iferr=json.Unmarshal(body,&req);err!=nil{
- w.WriteHeader(http.StatusBadRequest)
- logger.Errorf("cannotunmarshaltherequest:%s",err)
- return
- }
- iferr=validate.Struct(req);err!=nil{
- w.WriteHeader(http.StatusBadRequest)
- logger.Errorf("cannotvalidatetherequest:%s",err)
- return
- }
- iferr=app.EnrollCourse(req.CourseID,req.UserID);err!=nil{
- w.WriteHeader(http.StatusInternalServerError)
- logger.Errorf("cannotenrollthecourse:%s",err)
- return
- }
- }
请注意,编写执行相同逻辑的 CLI 命令很简单。唯一的区别是输入的来源。
- varuserIDstring
- varcourseIDstring
- varenroleCourseCmd=&cobra.Command{
- Use:"courseIDuserID",
- Args:cobra.MinimumNArgs(2),
- Run:func(cmd*cobra.Command,args[]string){
- iferr=app.EnrollCourse(courseID,userID);err!=nil{
- w.WriteHeader(http.StatusInternalServerError)
- logger.Errorf("cannotenrollthecourse:%s",err)
- return
- }
- },
- }
保持这些层的整洁和一致可能会给你的代码带来很多价值。它易于测试,职责明确,从哪里开始寻找要更改的代码更加明显。如果是与课程相关的错误并且是业务逻辑问题,则你将开始检查 Domain 或 Application 层。
另一方面,很难保持界限清晰和一致。它需要大量的自律、经验和至少几次迭代才能正确完成。这就是为什么很多人在这个领域失败的原因。
05 总结
组织代码很困难。更困难的是,应用程序的体系结构在其生命周期内可能会更改几次,进化。你可以从扁平结构开始,但最终会得到多个模块和许多子包。不要期望第一次就做对。它可能需要多次迭代并从其他人那里收集反馈。
此外,你可以根据应用程序的不同部分混合不同的代码组织方式。在你的业务逻辑部分,可以从模块化开始。但是,许多应用程序需要的实用程序就不适合用现有的包,你可以在那里遵循扁平结构模式。
原文链接:https://developer20.com/how-to-structure-go-code/
参考资料
[1]Robert Griesemer: https://en.wikipedia.org/wiki/Robert_Griesemer
[2]Rob Pike: https://www.youtube.com/watch?v=PAAkCSZUG1c
[3]pkg.go.dev: https://pkg.go.dev/
[4]doc.go: https://github.com/golang/go/blob/master/src/net/http/doc.go
[5]sake: http://tonyfischetti.github.io/sake/
[6]mage: https://github.com/magefile/mage
[7]zim: https://github.com/fugue/zim/
[8]opctl: https://opctl.io/
[9]不稳定: https://testing.googleblog.com/2020/12/test-flakiness-one-of-main-challenges.html
[10]golangci-lint: https://github.com/golangci/golangci-lint
[11]net/http/pprof: https://pkg.go.dev/net/http/pprof
[12]Clean Architecture: https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
[13]写了一本书: https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164
原文链接:https://mp.weixin.qq.com/s/uTCNXr5RoOjmlQ_mVjxnXg