在使用 Python 的时候,如果要判断一个字符串是否在另一个包含字符串的列表中,可以使用in 关键词,例如:
name_list = ['pm', 'kingname', '青南']
if 'kingname' in name_list:
print('kingname 在列表里面')
但是,Golang 是没有in这个关键词的,所以如果要判断一个字符串数组中是否包含一个特定的字符串,就需要一个一个对比:
package main
import "fmt"
func in(target string, str_array []string) bool {
for _, element := range str_array{
if target == element{
return true
}
}
return false
}
func main(){
name_list := []string{"pm", "kingname", "青南"}
target1 := "kingname"
target2 := "产品经理"
result := in(target1, name_list)
fmt.Println("kingname 是否在 name_list 中:", result)
result = in(target2, name_list)
fmt.Println("产品经理是否在 name_list 中:", result)
}
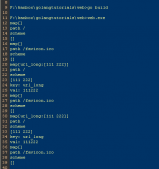
运行效果如下图所示:

但这种方式有一个弊端,就是要遍历整个字符串数组。如果数组里面有100万条数据,那么平均要遍历50万次才能找到。这是一个非常费时间的操作。
有没有什么办法可以优化这个操作呢?
如果是有序的整型数组,那么我们可以使用二分查找,把时间复杂度O(n)降到对数时间复杂度。字符串能不能也这样操作呢?实际上是可以的。
在 Golang 中,有一个排序模块sort,它里面有一个sort.Strings()函数,可以对字符串数组进行排序。同时,还有一个sort.SearchStrings()[1]函数,会用二分法在一个有序字符串数组中寻找特定字符串的索引。
结合两个函数,我们可以实现一个更高效的算法:
package main
import (
"fmt"
"sort"
)
func in(target string, str_array []string) bool {
sort.Strings(str_array)
index := sort.SearchStrings(str_array, target)
if index < len(str_array) && str_array[index] == target {
return true
}
return false
}
func main(){
name_list := []string{"pm", "kingname", "青南"}
target1 := "kingname"
target2 := "产品经理"
result := in(target1, name_list)
fmt.Println("kingname 是否在 name_list 中:", result)
result = in(target2, name_list)
fmt.Println("产品经理是否在 name_list 中:", result)
}
运行效果如下图所示:

其中,sort.Strings是一个 in-place 的修改方式,是直接修改的 str_array。修改以后str_array变成有序的字符串数组。接下来通过二分查找快速定位。如果找到了,那么返回目标字符串在排序后的列表中第一次出现的索引。如果没有找到,那么返回数组中最后一个元素的索引。所以只要 index 小于最后一个元素的索引,那么目标字符串肯定存在;如果等于最后一个元素的索引,但是值不等于最后一个元素,那么目标字符串就不存在于字符串数组中。
通过先排序再查询的方式,对于100万个元素的字符串数组,只需要查询20次左右就能确认字符串是否存在。速度大大提升。
最后考大家一个思考题。name_list一开始是乱序的字符串数组,在上图第23行,如果打印一下 name_list,打印出来的是经过排序的,还是没有经过排序的字符串数字?